Welcome to Dr. Link Check, a web-based service that scans your website and reports links that need your attention. If a link on your website no longer works or leads to a site with malicious or unwanted content, Dr. Link Check makes sure you are the first to know.
Getting started with Dr. Link Check is easy: simply go to the home page, enter the address of your website, and click on Start Check.

You will automatically be taken to the Overview report, where you can monitor the progress while the crawler goes through the site and examines all links it can find.
If you weren’t already logged into an account, a new one with a free Lite subscription will have been created for you. This account is temporary and will be deleted once you log out, unless you make it permanent by providing your name, email address and a password.
With your email address and password, you can log in to your account via the Login link from the top menu.
If you don’t remember your account password, use this link to request a password reset email.
After logging in, you can access your account settings by clicking on Account at the right-hand side of the title bar and selecting Account Settings from the drop-down menu.
A complete account requires your full name, email address, and a password that’s at least six characters long.
Please note that changing your account’s email address will not automatically update your billing email address (which is listed under Subscription Settings).
Your subscription determines which features are available and how many links can be checked per website.
The subscription plan you are currently on and the maximum number of links allowed per website are always visible at the bottom of the sidebar.
Clicking on the wrench icon opens the Subscription Settings dialog, which allows you to upgrade, downgrade, or cancel your subscription as well as update your billing information.
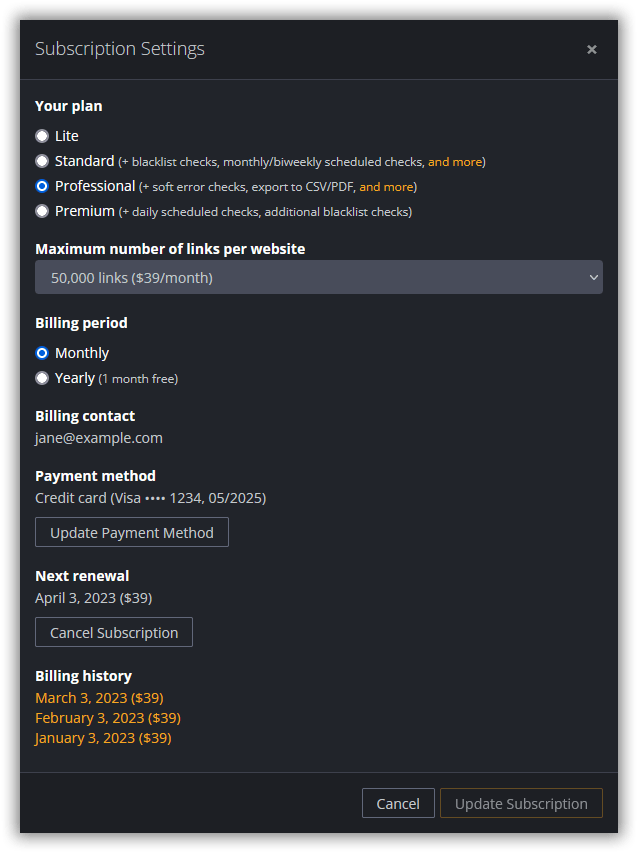
When upgrading to a more expensive plan, the change will take effect immediately, and you will be billed for the price difference. A downgrade or cancellation takes effect at the end of the current term. This means that after clicking the Cancel Subscription button, you still have full access to the service until the end of the current billing period.
Your subscription payments are securely processed by our e-commerce partner Paddle, which accepts all major credit cards and PayPal.
If you need your billing contact email address to be updated, please send us a message and we will make the change in Paddle’s ordering system – unfortunately, this is something that cannot be automated and has to be done manually.
A project comprises the settings and check results for a specific website.
The name of the currently active project is displayed at the top of the left sidebar. If you have several projects, you can switch between them by selecting an item from the menu.
To add a new project (and start a new link check), click the + button at the top of the sidebar.
You can configure the following settings for your project:
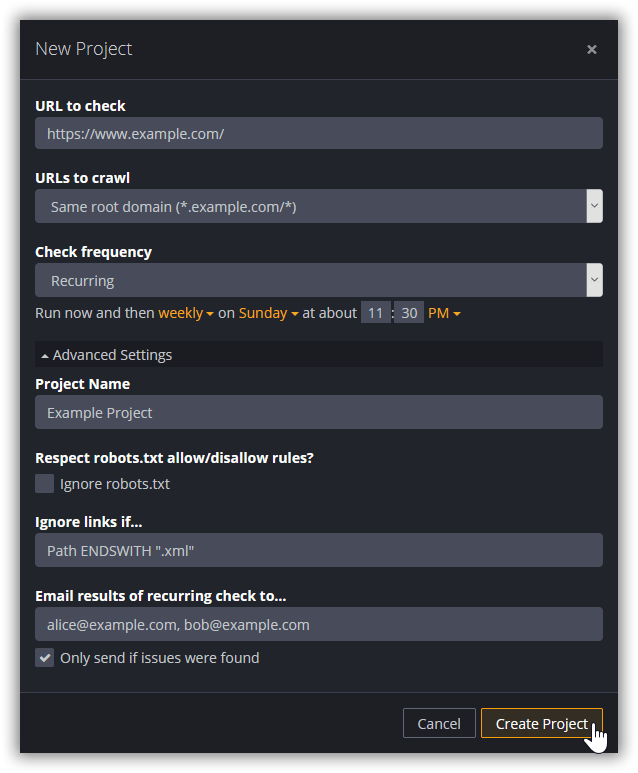
https://www.example.com/ as the start URL, our crawler considers https://subdomain.example.com/ to belong to your website. This is the default option and typically the right choice if you want your entire website, including all subdomains, to be checked.https://www.example.com/ as the start URL, our crawler considers https://subdomain.example.com/ to be an outbound link not belonging to your website.https://www.example.com/path/to/page1.html as the start URL, our crawler considers https://www.example.com/path/to/page2.html to be internal and https://www.example.com/index.html to be outbound.Additional settings are available in the Advanced Settings section:
Disallow and Allow rules for the user agents “Googlebot” (Google’s web crawler) and “*” (a wildcard for all other bots). Internal links that are disallowed for both “Googlebot” and “*” are excluded from the check. The start URL(s) and external links (pointing to other websites) are never excluded, regardless of what the robots.txt file specifies. Other robots.txt directives, such as Crawl-delay and Sitemap, are not supported. If you don’t want our crawler to obey to the rules found in a site’s robots.txt file, activate the Ignore robots.txt option.Dr. Link Check supports a rule language that allows you to define exactly which links to crawl for more links and which to ignore entirely. A simple crawl or ignore rule follows the pattern
<Property> <Comparison Operator> <Value>
with <Property> being one of the following:
Url: The full URL of the linkScheme: The scheme part of the URL, e.g. "https" or "mailto"Host: The hostname part of the URL, e.g. "example.com" or "www.example.com"Port: The port number part of the URL, e.g. 80 or 443Path: The absolute path of the URL, e.g. "/path/to/page" or "/"Query: The query string part of the URL, including the leading question mark, e.g. "?name=ferret&color=purple"PathAndQuery: The path and query parts of the URL, e.g. "/path/to/page?name=ferret&color=purple"HtmlElement: A CSS-like element selector to match a link’s HTML tag, e.g. "div.sidebar > a" (see this blog post for more information)LinkDepth: The distance between the link and the start URL, i.e. 0 for the start URL itself, 1 for links found directly on the start page, 2 for links found on pages linked from the start page, etc.LinkType: The location where the link was found in the code (enumeration value)
Ahref: Anchor element (<a href="URL">)ImgSrc: Image element (<img src="URL">)LinkStylesheet: Link stylesheet element (<link rel="stylesheet" href="URL">)ScriptSrc: Script element (<script src="URL">)MetaRefresh: Meta refresh element (<meta http-equiv="refresh" content="0; url=URL">)FrameSrc: Frame element (<frame src="URL"> or <iframe src="URL">)SocialMetaTag: Open Graph (Facebook) or Twitter Card meta tagCssImport: CSS @import ruleCssUrl: CSS url() functionJavaScriptLocation: JavaScript-triggered location changeJavaScriptOpen: JavaScript open(…) functionRobotsTxtSitemap: Link to an XML sitemap found in a robots.txt fileSitemapLoc: The URL was found in an XML sitemap fileOther: The URL was found somewhere else in the codeNoFollow: Specifies whether the link has a rel="nofollow" attribute (boolean value)The supported options for <Comparison Operator> are:
=: Is equal to!=: Is not equal toCONTAINS: Contains stringSTARTSWITH: Begins with stringENDSWITH: Ends with string>: Is greater than<: Is less than>=: Is greater than or equal to<=: Is less than or equal to<Value> can be either a string enclosed in double quotes ("example") or a number (123).
This allows you to construct simple rules like the ones below:
Scheme = "https"
Url STARTSWITH "https://www.example.com/path/"
Path ENDSWITH ".html"
Port = 81
HtmlElement = "img"
LinkDepth > 2
For more complex rules, the rule language offers support for logical operators (AND, OR) as well as parentheses for grouping expressions:
(Host = "example.com" OR Host ENDSWITH ".example.com") AND Path STARTSWITH "/path/"
You can also negate a rule by prepending NOT:
NOT (Path ENDSWITH ".png" OR Path ENDSWITH ".jpg" OR Path ENDSWITH ".gif")
If you want to check your website again, you don’t need to create a new project. Simply go the Overview report and click the Rerun Check button.
Your subscription includes a limited number of projects. If you reach this number, you can either upgrade to a higher plan or make room by deleting one of the existing projects.
To delete a project, open the drop-down menu in the sidebar, hover over the project’s menu item, and click on the trash icon.
In the sidebar on the left, you can select one of the the following reports.
The Overview report provides a high-level summary of the results of the link check.
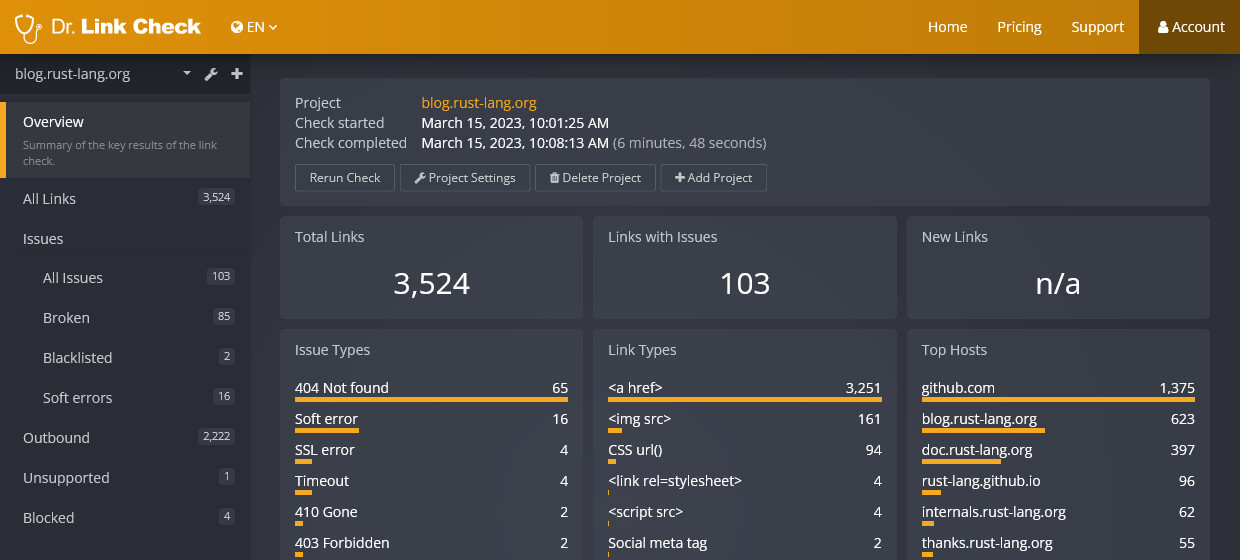
http, https, or tel).301 and 308. If a redirect is permanent, it makes sense to update the link to point to the new location. This avoids unnecessary HTTP requests and lowers the risk of breaking in the future.302, 303, and 307.Refresh HTTP response headers.nofollow (telling search engines to ignore the link for ranking purposes) or not. This information can be useful for SEO (search engine optimization) purposes, since dofollow links should only be set for high-quality and verified targets.Clicking one of these items takes you to a tabular report of matching links.
Dr. Link Check provides several tabular reports listing links by different criteria.
All Links: A report of all links found on the website.
Issues
http, https, data, or mailto (typical examples include javascript and tel links), which cannot be checked by our crawler. We recommend that you check these links manually.Each report has two columns:
../page2.html are expanded into full absolute URLs with a scheme (https://www.example.com/pages/page2.html) and fragments (#fragment) are removed.
By hovering over an entry in the link report and clicking on the Details button, you can view more information about the link, including the sources where it was found and any available redirection URLs.
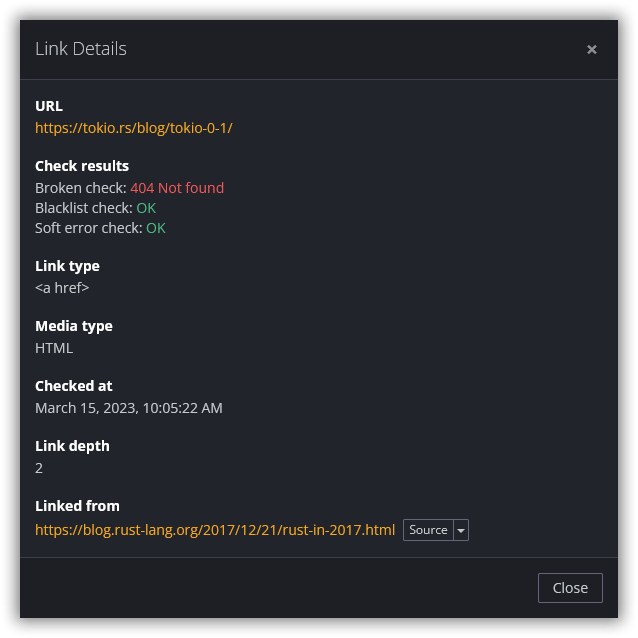
If there is an issue with the link, click the error message (such as 404 Not found) to open the documentation with more in-depth information, including tips on how to fix the problem.
If you want to know where exactly Dr. Link Check found the link in the code, click the Source button next to one of the entries in the Linked from section. The source document will be fetched from the server and displayed in a popup with the link locations highlighted.
By clicking on the down arrow next to the Source button and selecting Source link details, you can request the source link’s details to be loaded from the server and displayed in the Link Details dialog. This feature is especially useful for retracing the path our crawler took to arrive at a document because it allows you to jump from link to link up to the URL used to start the check.
A particularly powerful feature of Dr. Link Check is the ability to define filters to show only the links you are interested in. You can use filters for a variety of purposes, including the following:
To filter the results, click the Add button in the Filter bar on top of the link table and select the criteria you want to filter for:
"https" or "mailto")"www.example.com")"/path/to/page")0 for the start URL itself, 1 for links found directly on the start page, 2 for links found on pages linked from the start page, etc.)<a href>, <img src>, etc.)rel="nofollow" attributes (which instruct search engines to ignore the links for ranking purposes)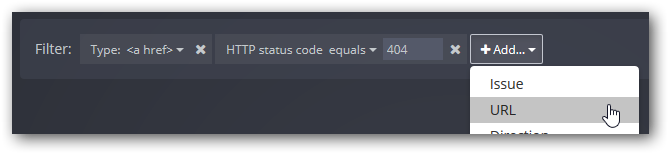
When adding multiple criteria, only links matching all those criteria will be returned. If you want to remove a criterion from the filter, click the x icon next to it.
Instead of creating a filter with the point and click method outlined above, you can also specify the filter in textual form. This feature is intended for advanced users who need to define filters that cannot be expressed via the normal user interface. To turn the filter into text mode, double-click on an empty spot in the filter bar.

A simple filter rule follows the pattern below:
<Property> <Comparison Operator> <Value>
<Property> can be any of the following:
Url: The full URL of the link (as a string)Scheme: The scheme part of the URL, e.g. "https" or "mailto" (string)Host: The hostname part of the URL, e.g. "example.com" or "www.example.com" (string)Port: The port number part of the URL, e.g. 80 or 443 (number value)Path: The absolute path of the URL, e.g. "/path/to/page" or "/" (string)Query: The query string part of the URL, including the leading question mark, e.g. "?name=ferret&color=purple" (string)Status: The current status of the link as part of the link check (as one of the enumeration values below)
Queued: The link is queued to be checkedInProgress: The link is currently being checkedChecked: The link was successfully checkedUnsupported: The link was not checked because it has an unsupported URL scheme (like “tel” in “tel:+1-555-1234567”)Aborted: The check of the link was abortedFailed: An error occurred while checking the linkBlocked: The link could not be checked because the request from our server was blockedLinkDepth: The distance between the link and the start URL, also known as click or page depth (number value)Direction: The direction at which the link is pointing (enumeration value)
Internal: The link points to an internal resourceOutbound: The link points to a resource outside of the current websiteIsNew: Specifies whether the link was added to the website since the last link check (Boolean value)IsChanged: Specifies whether the linked document was significantly updated since the last link check (Boolean value)RedirectType: Specifies how the link was redirected to a new location, if applicable (enumeration value)
Http301: HTTP redirect using a 301 (Moved Permanently) status codeHttp302: HTTP redirect using a 302 (Moved Temporarily) status codeHttp303: HTTP redirect using a 303 (See Other) status codeHttp307: HTTP redirect using a 307 (Temporary Redirect) status codeHttp308: HTTP redirect using a 308 (Permanent Redirect) status codeHttpRefresh: Redirect triggered by a Refresh HTTP headerMetaRefresh: Redirect triggered by a meta refresh HTML elementJavaScript: Automatic location change triggered by JavaScript codeFrame: Redirect implemented by loading the redirect target in a full-size frameRedirectUrl: The final URL in the redirect chain, if available (string)LinkType: The location where the link was found in the code (enumeration value)
AuthUrl: The URL which was used to authenticate with the serverStartUrl: The URL with which the link check was startedAhref: Anchor element (<a href="URL">)ImgSrc: Image element (<img src="URL">)LinkStylesheet: Link stylesheet element (<link rel="stylesheet" href="URL">)ScriptSrc: Script element (<script src="URL">)MetaRefresh: Meta refresh element (<meta http-equiv="refresh" content="0; url=URL">)FrameSrc: Frame element (<frame src="URL"> or <iframe src="URL">)SocialMetaTag: Open Graph (Facebook) or Twitter Card meta tagCssImport: CSS @import ruleCssUrl: CSS url() functionJavaScriptLocation: JavaScript-triggered location changeJavaScriptOpen: JavaScript open(…) functionRobotsTxtSitemap: Link to an XML sitemap found in a robots.txt fileSitemapLoc: The URL was found in an XML sitemap fileOther: The URL was found somewhere else in the codeMediaType: The content type of the linked resource (enumeration value)
Html: HTML documentImage: Image fileCss: CSS (style sheet) fileJavaScript: Script fileJson: JSON documentFont: Font fileXml: XML documentXmlSitemap: XML sitemapText: Human-readable text fileAudio: Audio fileVideo: Video fileBinary: Other binary (not human-readable) fileUnknown: File of unknown contentNoFollow: Specifies whether the link has a rel="nofollow" attribute (boolean value)NoIndex: Specifies whether a noindex directive was found, instructing web crawlers not to index the document (boolean value)DisallowedByRobotsTxt: Specifies whether the website’s robots.txt file instructs crawlers to ignore the link (boolean value)BrokenCheckResult: The result of checking whether the link is functionable (enumeration value)
Ok: The link works fineInvalidUrl: The link’s URL is not properly formattedUnsupportedScheme: The link’s URL uses a scheme that is not supportedHostNotFound: The hostname could not be resolvedConnectError: Failed to establish a connection to the serverSslHandshakeError: Failed to complete an SSL/TLS handshake with the serverSslCertProblem: The server’s SSL certificate failed verificationSendReceiveError: An error occurred while sending the request to the server or receiving the response from itTimeout: The server didn’t respond in timeHttpErrorCode: The server returned an HTTP error status codeTooManyRedirects: The link was redirected more than 20 timesBadContentEncoding: The transfer encoding could not be recognizedCrawlerTrap: A so-called crawler trap was detected, meaning the website produced an unusual high amount of irrelevant links without any new unique contentMxRecordNotFound: No MX record was found for the email address’s domain nameUnknownError: An error of unknown type occurredHttpResponseCode: The final HTTP status code received from the server, if available (number value)BlacklistCheckResult: The result of checking whether the link is blacklisted (enumeration value)
Ok: The link is not blacklistedBlacklisted: The link is blacklisted for hosting a phishing or malware attackSoftErrorCheckResult: The result of analyzing the page content for signs that indicate an error although the server returned a 2xx HTTP status code (enumeration value)
Ok: The page content doesn’t indicate an errorForSale: The link points to a domain or website for saleAdsOnly: The link points to a parked site filled with adsPlaceholder: The link points to a common placeholder pageOutOfService: The link points to an expired, suspended, or otherwise closed websiteNoContent: The link points to a page with no or very low contentDirectoryListing: The link points to a default page that lists the directory’s contentsErrorMessage: The page content indicates a 4xx or 5xx error (such as 404 Not Found or 500 Internal Server Error)The options for <Comparison Operator> are:
=: Is equal to!=: Is not equal toCONTAINS: Contains stringSTARTSWITH: Begins with stringENDSWITH: Ends with string>: Is greater than<: Is less than>=: Is greater than or equal to<=: Is less than or equal toFinally, <Value> is either a string enclosed in double quotes ("example.com"), a number (404), a boolean value (true, false), or an enumeration value depending on the chosen property (see above).
With this information, you can construct simple filters like the ones below:
Url STARTSWITH "https://www.example.com/path/"
Direction = Internal
MediaType != Html
Logical operators (AND, OR) and parentheses allow you to create more complex filters:
HttpResponseCode >= 500 AND HttpResponseCode <= 599
Direction = Outbound AND (LinkType = ScriptSrc OR LinkType = LinkStylesheet)
Expressions can also be negated by prepending them with NOT:
NOT (MediaType = Image OR MediaType = Audio OR MediaType = Video)
Once you have defined a custom report filter, you will notice a new button, Save as Custom Report, in the top right-hand corner. This button lets you save the current report and add a shortcut to the sidebar.

To delete a custom report, open it from sidebar and click on Delete Custom Report in the upper right corner of the report.
If you are on the Professional or Premium plan, you can export the entire results of a report to CSV or PDF format. The Export to CSV option generates a file that can be opened in spreadsheet software like Microsoft Excel or Apple Numbers for further processing. If you are looking for a document suitable for printing, choose the Export to PDF option.