Herzlich willkommen bei Dr. Link Check! Unser Online-Dienst prüft Websites schnell und zuverlässig auf kaputte und potenziell schädliche Links. Wenn ein Link Deiner Website nicht mehr funktioniert oder auf gefährliche Inhalte verweist, erfährst Du mit Dr. Link Check als Erstes davon und kannst das Problem rasch beheben.
Der Einstieg ist simpel: Ruf die Startseite auf, gib die Adresse Deiner Website ein und klicke auf Starte Check.

Du wirst automatisch zum Überlick-Report weitergeleitet, wo Du den Fortschritt beobachten kannst, während unser Crawler sich durch die Website arbeitet und die gefundenen Links auf Funktionstauglichkeit untersucht.
Wenn Du nicht bereits eingeloggt warst, wurde im Hintergrund ein neues Konto mit dem kostenlosen Lite-Paket für Dich angelegt. Dieses Konto ist temporär und wird gelöscht, sobald Du Dich wieder abmeldest – sofern Du das Konto nicht vervollständigst, indem Du Name, E-Mail-Adresse und Passwort angibst.
Mit E-Mail-Adresse und Passwort kannst Du Dich jederzeit rechts oben über den Menüeintrag Login bei Dr. Link Check einloggen.
Solltest Du Dein Passwort vergessen, lass es über diesen Link zurücksetzen.
Um nach dem Login Deine Kontodaten zu prüfen oder anzupassen, klicke rechts oben in der Leiste auf Konto und wähle den Menüeintrag Kontoeinstellungen.

Ein vollständiges Konto erfordert die Angabe von Vor- und Nachname, einer E-Mail-Adresse sowie eines Passwortes mit mindestens sechs Zeichen.
Bitte beachte, dass eine Änderung der E-Mail-Adresse nicht automatisch auch den Rechnungskontakt (siehe Vertragseinstellungen) aktualisiert.
Dein Vertrag legt fest, welche Funktionen Dir zur Verfügung stehen und wie viele Links pro Website gecheckt werden können.
Einen Kurzüberblick über den Umfang Deines Vertrag findest Du unten links in der Seitenleiste. Dort werden Dir das aktuell gewählte Paket und die Höchstzahl an Links angezeigt.
Durch einen Klick auf das Schraubenschlüsselsymbol öffnet sich der Vertragseinstellungen-Dialog. Hier kannst Du Deine Vertragsleistungen anpassen, den Vertrag kündigen oder Deine Zahlungsinformationen aktualisieren.
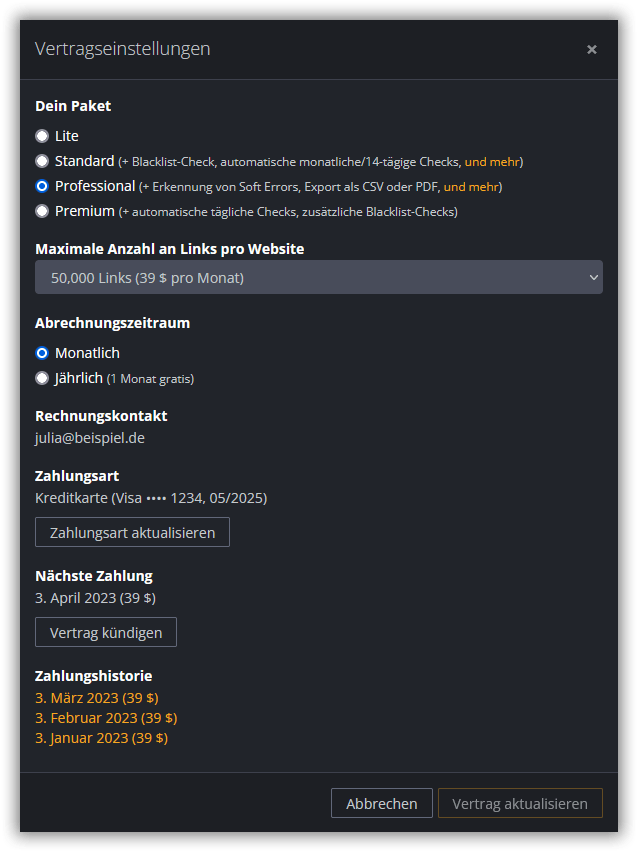
Wenn Du auf ein teureres Paket umsteigst, wird Dein Vertrag unmittelbar angepasst und Dir die Preisdifferenz in Rechnung gestellt. Der Wechsel in ein kleineres Paket oder eine Kündigung werden erst zum Ende des laufenden Abrechnungszyklus wirksam. Nach einem Klick auf Vertrag kündigen steht Dir also bis zum Ende der Vertragslaufzeit weiterhin der volle Funktionsumfang zur Verfügung.
Sämtliche Zahlungen werden von unserem Partner Paddle abgewickelt und können per Kreditkarte oder PayPal erfolgen.
Wenn Du den Rechnungskontakt für Deinen Vertrag anpassen möchtest, schick uns bitte eine kurze Nachricht. Aufgrund technischer Einschränkungen im Bestellsystem von Paddle kann eine Änderung der E-Mail-Adresse leider nicht automatisch erfolgen, sondern muss von uns manuell vorgenommen werden.
Ein Projekt umfasst die Einstellungen und Prüfergebnisse für eine bestimmte Website.
Der Name des aktuellen Projekts wird oben in der Seitenleiste angezeigt. Durch einen Klick öffnet sich das Projektmenü, über das Du zwischen verschiedenen Projekten wechseln kannst.
Um ein neues Projekt zu erstellen (und einen neuen Check zu starten), klicke auf das +-Symbol am oberen Rand der Seitenleiste.

Du kannst die folgenden Einstellungen für Dein Projekt vornehmen:
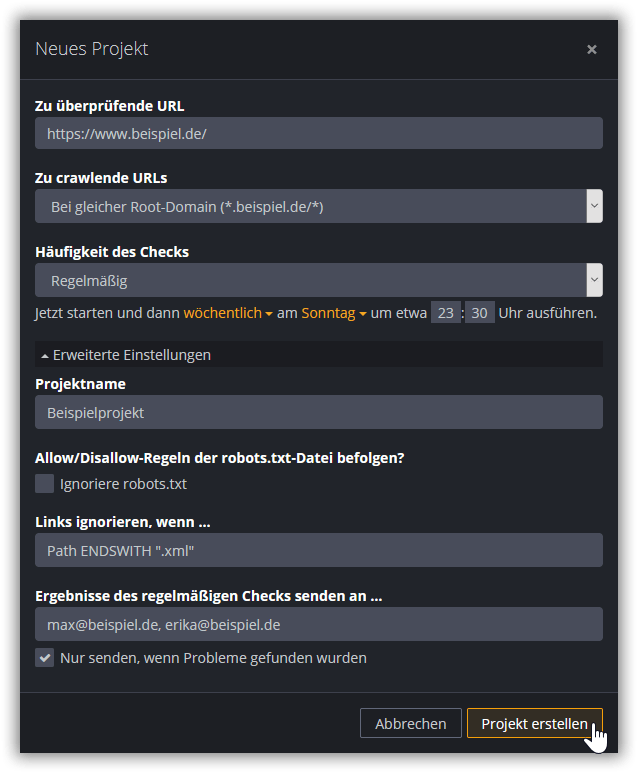
https://www.beispiel.de/ als Start-URL angegeben, gilt https://subdomain.beispiel.de/ als Teil Deiner Website, da beide URLs die Root-Domain beispiel.de enthalten. Mit dieser Option liegst Du richtig, wenn Du eine komplette Website einschließlich aller Subdomains prüfen lassen möchtest.https://www.beispiel.de/ als Start-URL angegeben, gilt https://subdomain.beispiel.de/ als ausgehender Link und wird dementsprechend zwar geprüft, jedoch nicht nach weiteren Links durchforstet.https://www.beispiel.de/pfad/zu/seite1.html als Start-URL angegeben, gilt https://www.beispiel.de/pfad/zu/seite2.html als intern, https://www.beispiel.de/index.html jedoch als ausgehend.Zusätzliche Möglichkeiten zur Konfiguration des Projekts findest Du unter Erweiterte Einstellungen:
Disallow- und Allow-Regeln für „Googlebot“ (der Webcrawler von Google) und „“ (Platzhalter für sonstige Crawler). Verbieten die Regeln sowohl für „Googlebot“ als auch für „“ den Zugriff auf einen bestimmten internen Link, wird dieser vom Check ausgeschlossen. Die Start-URL(s) und externe Links (die auf fremde Websites verweisen) werden jedoch immer überprüft, unabhängig vom Inhalt der robots.txt-Datei. Sonstige Anweisungen, wie beispielsweise Crawl-delay und Sitemap, unterstützt der Crawler momentan nicht. Möchtest Du eine Website ohne Berücksichtigung der robots.txt-Datei prüfen lassen, aktiviere die Option Ignoriere robots.txt.Eine einfache Crawl- oder Ignorierregel ist wie folgt aufgebaut:
<Eigenschaft> <Vergleichsoperator> <Wert>
Als <Eigenschaft> sind folgende Schlüsselwörter möglich:
Url: Die vollständige URL des LinksScheme: Das Schema der URL, beispielsweise "https" oder "mailto"Host: Die Host-Komponente der URL, beispielsweise "beispiel.de" oder "www.beispiel.de"Port: Der Port der URL als Zahlenwert, beispielsweise 80 oder 443Path: Der absolute Pfad der URL, beispielsweise "/pfad/zur/seite" oder "/"Query: Der Query-String der URL, einschließlich des vorangestellten Fragezeichens, beispielsweise "?name=frettchen&farbe=lila"PathAndQuery: Die Kombination aus Pfad und Query-String der URL, beispielsweise "/pfad/zur/seite?name=frettchen&farbe=lila"HtmlElement: Ein CSS-ähnlicher Selektor zur Identifizierung des HTML-Tags eines Links, beispielsweise "div.sidebar > a" (weitere Informationen findest Du in diesem Blog-Post)LinkDepth: Die Entfernung des Links von der Start-URL, also 0 für die Start-URL selbst, 1 für direkt auf der Startseite gefundene Links, 2 für auf von der Startseite verlinkten Seiten gefundene Links, etc.LinkType: Die Art des Links (Aufzählungswert)
Ahref: Standard-Link, typischerweise in der Form <a href="URL">Link>/a>ImgSrc: Link zu einem eingebetteten Bild, typischerweise in der Form <img src="URL">LinkStylesheet: Link zu einer CSS-Datei in der Form <link href="URL" rel="stylesheet">ScriptSrc: Link zu einer externen Skriptdatei in der Form <script src="URL">>/script>MetaRefresh: Link, zu dem per Meta Refresh (<meta http-equiv="refresh" content="0; url=URL">) umgeleitet wurdeFrameSrc: Link zu einem per frame (<frame src="URL">) oder iframe (<iframe src="URL">) in die Seite eingebetteten DokumentSocialMetaTag: Link, der in einem Open Graph (Facebook) oder Twitter Card Meta-Tag gefunden wurdeCssImport: Link zu einer CSS-Datei, die per @import von einer anderen CSS-Datei eingebunden wurdeCssUrl: Link zu einer Datei, die von einem CSS-Dokument mittels url(…) eingebunden wurdeJavaScriptLocation: JavaScript-Anweisung, die zu einer neuen Adresse umleitetJavaScriptOpen: open(…) JavaScript-Anweisung, die eine URL in einem neuen Browserfenster öffnetRobotsTxtSitemap: Link zur einer XML-Sitemap, der in einer robots.txt-Datei gefunden wurdeSitemapLoc: Link, der in einer XML-Sitemap-Datei gefunden wurdeOther: Der Link wurde an nicht näher spezifizierter Stelle im Code gefundenNoFollow: Gibt an, ob der Link über ein rel="nofollow"-Attribut verfügt (Boolean-Wert)Unterstützte <Vergleichsoperator>en sind:
=: Ist gleich!=: Ist ungleichCONTAINS: Enthält ZeichenketteSTARTSWITH: Beginnt mit ZeichenketteENDSWITH: Endet mit Zeichenkette>: Ist größer als<: Ist kleiner als>=: Ist größer oder gleich<=: Ist kleiner oder gleich<Value> kann entweder eine in doppelte Anführungszeichen gesetzte Zeichenkette ("beispiel") oder eine Zahl (123) sein.
Damit lassen sich zum Beispiel folgende einfache Regeln konstruieren:
Scheme = "https"
Url STARTSWITH "https://www.beispiel.de/pfad/"
Path ENDSWITH ".html"
Port = 81
HtmlElement = "img"
LinkDepth > 2
Mit Hilfe von logischen Operatoren (AND, OR) und Klammern kannst Du Ausdrücke zu komplexeren Regeln zusammensetzen:
(Host = "beispiel.de" OR Host ENDSWITH ".beispiel.de") AND Path STARTSWITH "/pfad/"
Das Voranstellen von NOT negiert einen Ausdruck:
NOT (Path ENDSWITH ".png" OR Path ENDSWITH ".jpg" OR Path ENDSWITH ".gif")
Wenn Du eine Website noch einmal prüfen lassen möchtest, musst Du dafür kein neues Projekt anlegen. Öffne stattdessen einfach den Überblick-Report und klicke auf Check neu starten.
Dein Vertrag umfasst eine begrenzte Zahl an Projekten. Wenn Du diese Zahl erreichst, kannst Du entweder in ein höheres Paket wechseln oder eines des bestehenden Projekte löschen.
Um ein Projekt zu löschen, öffne das Projektmenü links oben in der Seitenleiste, bewege den Mauszeiger zum entsprechenden Eintrag und klicke dann auf das Papierkorbsymbol.
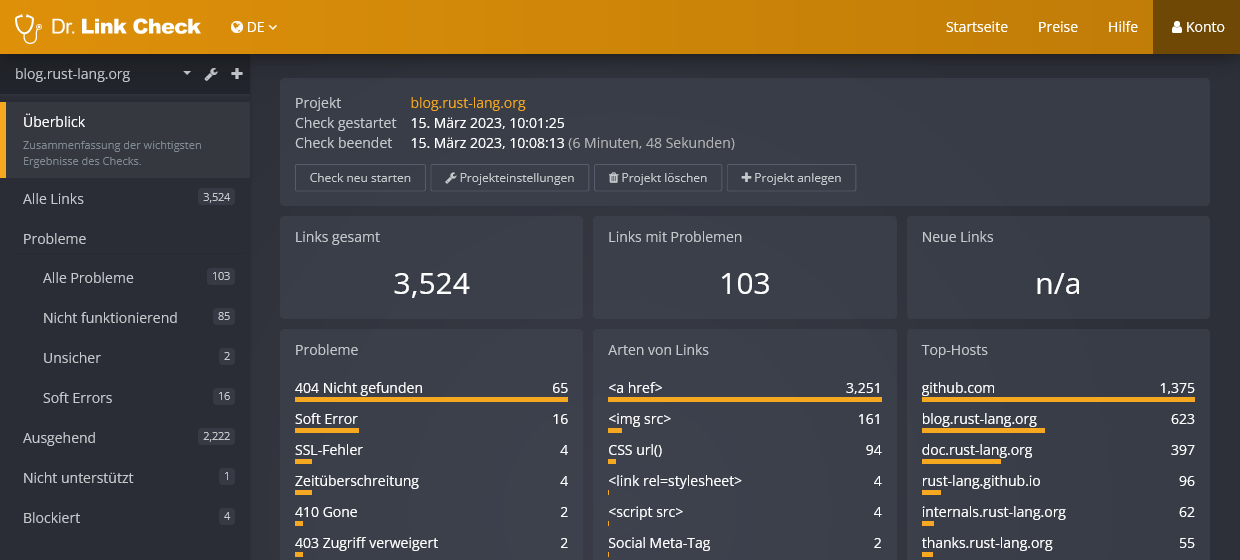
Über die Seitenleiste am linken Rand hast Du Zugriff auf folgende Berichte.
Der Überblick-Report liefert Dir eine Zusammenfassung der Ergebnisse des Checks.
http, https oder tel).301 und 308. Im Falle einer permanenten Weiterleitung empfiehlt es sich, den Link direkt auf die neue URL zu aktualisieren. Dies reduziert die Anzahl notwendiger HTTP-Requests und mindert die Gefahr, dass ein Link später einmal nicht mehr zum gewünschten Ziel führen wird.302, 303 und 307.Refresh-HTTP-Header.nofollow gekennzeichnet sind oder nicht. Das Attribut rel="nofollow" weist Suchmaschinen an, einem Link beim Ranking keine Bedeutung beizumessen.Durch einen Klick auf einen der Einträge gelangst Du zum Detailbericht mit den entsprechenden Links.
Dr. Link Check stellt Dir verschiedene tabellarische Berichte zur Verfügung, um die gefundenen Links nach unterschiedlichen Kriterien zu filtern.
http, https, data oder mailto verwenden.Die Berichte setzen sich aus zwei Spalten zusammen:
../seite2.html) werden in vollständige absolute URLs mit Schema (https://www.beispiel.de/seiten/seite2.html) umgewandelt. Zudem werden URL-Fragmente (#fragment) entfernt.
Indem Du den Mauszeiger zu einem Eintrag im Link-Report bewegst und auf Details klickst, kannst Du weitere Informationen zu dem betreffenden Link abrufen. Diese beinhalten beispielsweise die verlinkenden Seiten und sämtliche URLs der Weiterleitungskette, falls vorhanden.
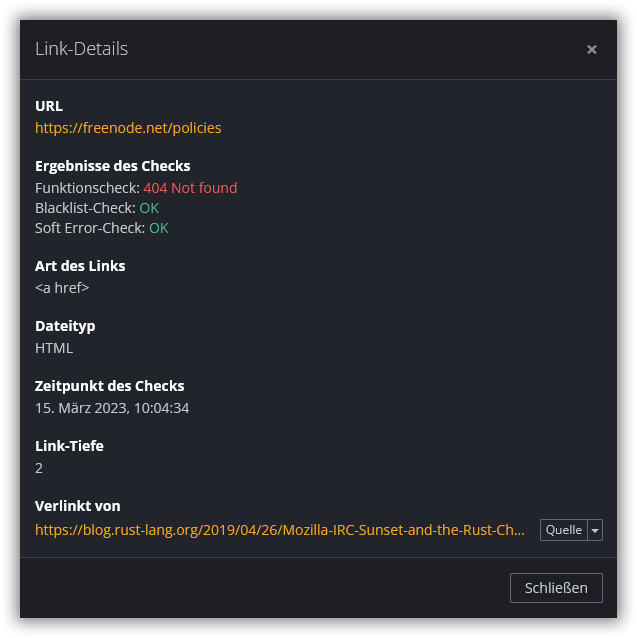
Wurde beim Funktionscheck ein Fehler festgestellt, liefert Dir ein Klick auf die Fehlermeldung weitere Informationen, einschließlich Tipps zur Behebung des Problems.
Ein Klick auf Quelle neben einem der Einträge unter Verlinkt von zeigt Dir, wo genau Dr. Link Check den aktuellen Link im Code gefunden hat. In einem separaten Fenster werden der vom Server abgerufene Quellcode dargestellt und die Fundstellen des Links farblich hervorgehoben.
Über den kleinen Pfeil neben der Quelle-Schaltfläche gelangst Du zum Menüeintrag Quelllink anzeigen. Hierüber kannst Du Dir die Details der verlinkenden Seite anzeigen lassen. Diese Funktion ist insbesondere dann nützlich, wenn Du nachvollziehen möchtest, wie unser Crawler zu einem bestimmten Link gelangt ist – Link für Link kannst Du den Pfad durch die Website bis zur Startseite zurückverfolgen.
Um lediglich diejenigen Links anzeigen zu lassen, die für Dich von Interesse sind, kannst Du die Filterfunktion von Dr. Link Check nutzen. Diese Funktion ist äußerst vielseitig einsetzbar, beispielsweise für folgende Reports:
Um einen Filter zu erstellen, klicke auf Hinzufügen in der Filter-Leiste oberhalb der Ergebnistabelle und wähle eines der Filterkriterien:
"https" oder "mailto")"www.beispiel.de")"/pfad/zur/seite")0 für die Start-URL selbst, 1 für direkt auf der Startseite gefundene Links, 2 für auf von der Startseite verlinkten Seiten gefundene Links, etc.)<a href>, <img src>, etc.)rel="nofollow" (welches Suchmaschinen anweist, den Link beim Ranking der Zielseite zu ignorieren)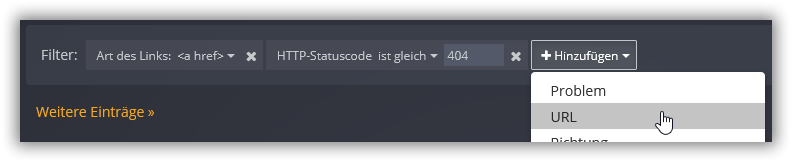
Wenn Du mehrere Filterkriterien hinzufügst, werden nur diejenigen Links angezeigt, die sämtlichen Kriterien entsprechen. Um einen Teil des Filters zu entfernen, klicke auf das neben dem entsprechenden Eintrag dargestellte x-Icon.
Anstatt einen Filter per Mausklick zu erzeugen, kannst Du die Filterregel auch in Textform angeben. Dieses Features richtet sich an fortgeschrittene Benutzer und ermöglicht die Definition von Filtern, die sich über die normale Benutzeroberfläche nicht abbilden lassen. Den Texteingabemodus aktivierst Du über einen Doppelklick auf eine freie Stelle in der Filterleiste.

Eine einfache Filterregel ist wie folgt aufgebaut:
<Eigenschaft> <Vergleichsoperator> <Wert>
<Eigenschaft> kann dabei eines der folgenden Schlüsselwörter sein:
Url: Die vollständige URL des Links (als Zeichenkette)Scheme: Das Schema der URL, beispielsweise "https" oder "mailto" (Zeichenkette)Host: Die Host-Komponente der URL, beispielsweise "beispiel.de" oder "www.beispiel.de" (Zeichenkette)Port: Der Port der URL als Zahlenwert, beispielsweise 80 oder 443 (Zahlenwert)Path: Der absolute Pfad der URL, beispielsweise "/pfad/zur/seite" oder "/" (Zeichenkette)Query: Der Query-String der URL, einschließlich des vorangestellten Fragezeichens, beispielsweise "?name=frettchen&farbe=lila" (Zeichenkette)Status: Der aktuelle Prüfstatus des Links (als einer der folgenden Aufzählungswerte)
Queued: Der Link befindet sich in der Warteschlange und wird in Kürze geprüftInProgress: Der Link wird gerade geprüftChecked: Die Überprüfung des Links wurde erfolgreich abgeschlossenUnsupported: Der Link konnte nicht geprüft werden, da die URL ein nicht unterstütztes Schema aufweist (wie beispielsweise „tel“ in „tel:+1-555-1234567“)Aborted: Die Überprüfung des Links wurde vorzeitig abgebrochenFailed: Bei der Überprüfung des Links ist ein unerwarteter Fehler aufgetretenBlocked: Die Überprüfung des Links konnte nicht vollständig abgeschlossen werden, da der Zielserver die Anfrage blockiert hatLinkDepth: Die Entfernung des Links von der Start-Url, häufig auch als Klicktiefe bezeichnet (Zahlenwert)Direction: Die Richtung, in die der Link zeigt (Aufzählungswert)
Internal: Der Link verweist auf ein Ziel innerhalb der geprüften WebsiteOutbound: Der Link verweist auf eine fremde WebsiteIsNew: Gibt an, ob der Link seit dem letzten Check neu hinzugekommen ist (Boolean-Wert)IsChanged: Gibt an, ob sich der Inhalt des verlinkten Dokuments seit dem letzten Check wesentlich geändert hat (Boolean-Wert)RedirectType: Gibt gegebenenfalls an, auf welche Weise der Link zu einer neuen Adresse weitergeleitet wurde (Aufzählungswert)
Http301: HTTP-Weiterleitung mit Statuscode 301 (Moved Permanently)Http302: HTTP-Weiterleitung mit Statuscode 302 (Moved Temporarily)Http303: HTTP-Weiterleitung mit Statuscode 303 (See Other).Http307: HTTP-Weiterleitung mit Statuscode 307 (Temporary Redirect)Http308: HTTP-Weiterleitung mit Statuscode 308 (Permanent Redirect)HttpRefresh: Weiterleitung mittels Refresh-HTTP-HeaderMetaRefresh: Weiterleitung per Meta-Refresh-TagJavaScript: Automatische Weiterleitung per JavaScript-CodeFrame: Weiterleitung, bei der die Zielseite als Frame eingebettet wirdRedirectUrl: Die letzte URL in der Weiterleitungskette, sofern verfügbar (Zeichenkette)LinkType: Die Art des Links (Aufzählungswert)
AuthUrl: Link, über den sich der Crawler bei der Website angemeldet bzw. authentifiziert hatStartUrl: Link, mit dem der Check begonnen hatAhref: Standard-Link, typischerweise in der Form <a href="URL">Link>/a>ImgSrc: Link zu einem eingebetteten Bild, typischerweise in der Form <img src="URL">LinkStylesheet: Link zu einer CSS-Datei in der Form <link href="URL" rel="stylesheet">ScriptSrc: Link zu einer externen Skriptdatei in der Form <script src="URL">>/script>MetaRefresh: Link, zu dem per Meta Refresh (<meta http-equiv="refresh" content="0; url=URL">) umgeleitet wurdeFrameSrc: Link zu einem per frame (<frame src="URL">) oder iframe (<iframe src="URL">) in die Seite eingebetteten DokumentSocialMetaTag: Link, der in einem Open Graph (Facebook) oder Twitter Card Meta-Tag gefunden wurdeCssImport: Link zu einer CSS-Datei, die per @import von einer anderen CSS-Datei eingebunden wurdeCssUrl: Link zu einer Datei, die von einem CSS-Dokument mittels url(…) eingebunden wurdeJavaScriptLocation: JavaScript-Anweisung, die zu einer neuen Adresse umleitetJavaScriptOpen: open(…) JavaScript-Anweisung, die eine URL in einem neuen Browserfenster öffnetRobotsTxtSitemap: Link zur einer XML-Sitemap, der in einer robots.txt-Datei gefunden wurdeSitemapLoc: Link, der in einer XML-Sitemap-Datei gefunden wurdeOther: Der Link wurde an nicht näher spezifizierter Stelle im Code gefundenMediaType: Der Typ der verlinkten Datei (Aufzählungswert)
Html: HTML-DokumentImage: BilddateiCss: CSS-DateiJavaScript: SkriptdateiJson: JSON-DokumentFont: Font-DateiXml: XML-DokumentXmlSitemap: XML-SitemapText: TextdokumentAudio: AudiodateiVideo: VideodateiBinary: Datei in einem nicht näher spezifizierten BinärformatUnknown: Datei mit unbekanntem InhaltNoFollow: Gibt an, ob der Link über ein rel="nofollow"-Attribut verfügt (Boolean-Wert)NoIndex: Gibt an, ob eine noindex-Anweisung gefunden wurde, mit der Crawler angewiesen werden, die verlinkte Seite zu ignorieren und nicht zu indexieren (Boolean-Wert)DisallowedByRobotsTxt: Gibt an, ob die robots.txt-Datei der betreffenden Website Google und anderen Crawlern den Zugriff auf den Link verbietetBrokenCheckResult: Das Ergebnis des Funktionschecks (Aufzählungswert)
Ok: Der Link funktioniert problemlosInvalidUrl: Der Aufbau der URL ist fehlerhaftUnsupportedScheme: Die URL verwendet ein nicht unterstütztes SchemaHostNotFound: Der Domainname konnte nicht per DNS aufgelöst werdenConnectError: Es konnte keine Verbindung zum Server hergestellt werdenSslHandshakeError: Der SSL/TLS-Handshake mit dem Server ist fehlgeschlagenSslCertProblem: Das SSL-Zertifikat des Servers hat die Gültigkeitsprüfung nicht bestandenSendReceiveError: Beim Senden der Anfrage an den Server oder dem Empfang der Antwort ist ein Fehler aufgetretenTimeout: Der Server hat nicht in der vorgegebenen Zeit geantwortetHttpErrorCode: Der Server hat mit einem HTTP-Statuscode geantwortet, der auf einen Fehler hinweistTooManyRedirects: Der Link wurde mehr als 20-mal weitergeleitetBadContentEncoding: Die Art der Komprimierung („Content-Encoding“) konnte nicht erkannt werden.CrawlerTrap: Eine sogenannte „Crawler Trap“ wurde erkannt, bei der eine Website eine ungewöhnliche hohe Zahl an irrelevanten Links ohne neue Inhalte generiertMxRecordNotFound: Für den Domainnamen der E-Mail-Adresse ist kein Mailserver konfiguriertUnknownError: Ein Fehler unbekannten Typs ist aufgetretenHttpResponseCode: Der vom Server empfangene, finale HTTP-Statuscode, sofern verfügbar (Zahlenwert)BlacklistCheckResult: Das Ergebnis des Blacklist-Checks (Aufzählungswert)
Ok: Der Link wurde auf keiner Blacklist gefundenBlacklisted: Der Link wurde auf mindestens einer Blacklist gefunden und verweist auf eine Phishing- oder MalwareseiteSoftErrorCheckResult: Das Ergebnis der Analyse des Seiteninhalts auf Anzeichen eines Fehlers, obwohl der Server mit einem HTTP-Statuscode 2xx keine Probleme gemeldet hat (Aufzählungswert)
Ok: Der Seiteninhalt deutet nicht auf einen Fehler hinForSale: Der Link führt zu einer Domain oder Website, die zum Verkauf stehtAdsOnly: Der Link führt zu einer geparkten Website, die ausschließlich mit Werbung gefüllt istPlaceholder: Der Link führt einer Platzhalterseite ohne weitere InhalteOutOfService: Der Link führt einer Website, deren Domain abgelaufen, gesperrt oder anderweitig außer Betrieb genommen wurdeNoContent: Der Link führt zu einer Seite, die keine oder kaum Inhalte bereitstelltDirectoryListing: Der Link führt zu einer Standardseite, die den Inhalt des aktuellen Verzeichnisses auf dem Server ausgibtErrorMessage: Der Seiteninhalt deutet auf einen 4xx- oder 5xx-Fehler hin (etwa 404 Not Found or 500 Internal Server Error)Den <Vergleichsoperator> kannst Du aus folgender Liste wählen:
=: Ist gleich!=: Ist ungleichCONTAINS: Enthält ZeichenketteSTARTSWITH: Beginnt mit ZeichenketteENDSWITH: Endet mit Zeichenkette>: Ist größer als<: Ist kleiner als>=: Ist größer oder gleich<=: Ist kleiner oder gleichJe nach gewählter Eigenschaft (siehe oben), ist <Wert> entweder eine in doppelte Anführungszeichen gesetzte Zeichenkette ("beispiel.de"), eine Zahl (404), ein Boolean-Wert (true, false) oder ein Aufzählungswert.
Mit diesem Wissen kannst Du nun einfache Filterregeln konstruieren:
Url STARTSWITH "https://www.beispiel.de/pfad/"
Direction = Internal
MediaType != Html
Logische Operatoren (AND, OR) und Klammern ermöglichen komplexere Filter:
HttpResponseCode >= 500 AND HttpResponseCode <= 599
Direction = Outbound AND (LinkType = ScriptSrc OR LinkType = LinkStylesheet)
Mit NOT lassen sich Filterausdrücke negieren:
NOT (MediaType = Image OR MediaType = Audio OR MediaType = Video)
Über die Schaltfläche Als eigenen Report speichern rechts oberhalb der Ergebnistabelle kannst Du den aktuellen Report speichern. Er erscheint anschließend als neuer Eintrag unter Eigene Reports in der Liste am linken Rand.
Um einen eigenen Report zu löschen, öffne ihn über die Seitenleiste und klicke anschließend auf die Schaltfläche Report löschen oben rechts.
Wenn Du unser Professional- oder Premium-Paket einsetzt, kannst Du komplette Reports als CSV- oder PDF-Datei exportieren. Die Option Exportieren als CSV generiert eine Datei, die mit einer Tabellenkalkulation wie Microsoft Excel oder Apple Numbers geöffnet und weiterverarbeitet werden kann. Benötigst Du stattdessen einen druckreifen Bericht, wähle die Exportieren als PDF-Option.
