Dr. Link Check lets you export link reports in CSV format so you can analyze the results using third-party tools.
One of our larger customers recently asked why he couldn’t open and analyze his CSV export file in Microsoft Excel. I explained that Excel has a limit of 1,048,576 rows, which means it can’t handle CSV files that go beyond that number. My suggestion was to either use a dedicated CSV viewer or, even better, import the CSV file into a database and work with it using SQL.
In this post, I’ll walk you through how to create an SQLite database, import a CSV file, and run SQL queries to get the data you need. SQLite is a lightweight and powerful database engine that’s easy to set up and free to use.
To keep things simple, I’ll be using SQLiteStudio as a graphical client for working with SQLite. It’s much easier than using the command line, especially when you want features like a visual schema editor, a spreadsheet-style data browser, and a built-in SQL editor with autocomplete.
Go to sqlitestudio.pl and click the Download button. SQLiteStudio is free and available for Windows, macOS, and Linux. It comes with SQLite bundled in, so there’s nothing else you need to install.
Once the installation is complete, launch SQLiteStudio to get started.
The first step is to create a new database file.
Click the Add a database button in the toolbar.

In the dialog that opens, click the green Create a new database file button. Choose a folder where you want to save the database, then enter a filename (for example, test.db).

Click OK to finish. Your new SQLite database is now ready to use.
Double click the database entry in the Databases tree to establish a connection to the database.
With your database created and opened, the next step is to import your CSV data into a new table.
Open the Tools menu and select Import.

In the import wizard, enter a name for the new table. For example, you can name it export, then click Next to continue.

Select your CSV file and review the import settings. If the data does not line up correctly, try changing the Field separator setting. Some files use commas, while others may use semicolons depending on how they were generated.

Click Finish to begin the import. Once it is complete, the new table will appear under Tables in the database tree on the left.

You can now start querying your data using SQL. Go to the Tools menu and choose Open SQL editor. This opens a new window where you can enter SQL statements. To run a statement, click the blue Execute command button at the top.

For the following examples, I’ll assume that you created a table named export from a CSV file exported using Dr. Link Check’s Export to CSV feature.
Let’s start simple by querying all URLs that, according to Dr. Link Check, returned a 404 error:
SELECT *
FROM export
WHERE BrokenCheck = '404 Not found';

The next example returns all links with any issues, ordered by URL:
SELECT *
FROM export
WHERE BrokenCheck <> 'OK' OR BlacklistCheck <> 'OK' OR ParkedDomainCheck <> 'OK'
ORDER BY Url;
If you want to query all internal links that were permanently redirected, use this SQL statement:
SELECT *
FROM export
WHERE Direction = 'Internal' AND RedirectType = 'Permanent';
Using the LIKE operator, you can get all mailto: links:
SELECT *
FROM export
WHERE Url LIKE 'mailto:%';
With a GROUP BY clause, you can get all URL schemes and the count for each scheme in descending order:
SELECT substr(Url, 0, instr(Url, ':')) AS scheme, count(*) as count
FROM export
WHERE scheme <> ''
GROUP BY scheme
ORDER BY count DESC;
Another useful query returns all non-secure http:// links that redirect to the same URL using the https:// scheme:
SELECT *
FROM export
WHERE Url LIKE 'http://%' AND RedirectUrl = 'https://' || substr(RedirectUrl, length('https://') + 1);
Now it gets a bit more advanced. The following query counts the number of links by file extension:
SELECT
-- Everything right to the last dot in the URL
lower(substr(url_without_query_string, length(rtrim(url_without_query_string, replace(url_without_query_string, '.', ''))) + 1)) AS file_ext,
count(*) as count
FROM (
-- Remove query string from URL
SELECT CASE WHEN instr(url, '?') > 0 THEN substr(url, 0, instr(url, '?')) ELSE url END AS url_without_query_string
FROM export
WHERE url REGEXP '^(https?|ftp)://' -- Only query http://, https://, and ftp:// URLs
)
WHERE file_ext <> '' AND instr(file_ext, '/') = 0
GROUP BY file_ext
ORDER BY count DESC;
The last practical example allows you to compare the results of two exports and find which URLs were added or removed. This assumes that you imported the first export into a table called export_a and the second into a table called export_b:
SELECT 'Removed' as action, a.url
FROM export_a a
LEFT JOIN export_b b ON b.url = a.url
WHERE b.url IS NULL
UNION ALL
SELECT 'Added' as action, b.url
FROM export_b b
LEFT JOIN export_a a ON a.url = b.url
WHERE a.url IS NULL;
If you are new to SQL, visit sql-easy.com for a short, interactive course that covers the basics.
SQLite is a powerful tool for working with CSV files, especially when you need to handle large datasets that other tools like Excel cannot manage. When paired with SQLiteStudio as a graphical front end, it becomes easy to set up and use.
If you are exporting reports from Dr. Link Check and want more control over how you filter, sort, or analyze the data, give this workflow a try.
Links are the backbone of the web and play an essential role in SEO and how well a website ranks in search engines like Google or Bing. Based on their destination, links can be classified into three categories, each serving its own purpose:
Together, these links form what’s known as a website’s “link profile.” While each link type plays an important role in shaping this profile, this post will focus on outbound links.
So why exactly do outbound links matter so much? They’re essential for building your website’s credibility. By linking to trustworthy, relevant sources, you show readers that your content is well-researched and backed by reliable references. This helps establish your site as an authority. Outbound links also improve the user experience by giving readers quick access to related information without making them search elsewhere.
From an SEO standpoint, links to authoritative sites signal quality and relevance, which can positively impact search rankings. But remember, not all outbound links are created equal. Links to low-quality or even malicious sites can harm your site’s reputation, and broken links can frustrate users and affect SEO. Since links may break over time or lead to unexpected content if a domain changes hands, it’s essential to regularly check and update outbound links to keep them valuable and trustworthy.
An easy way to keep track of your outbound links is by using Dr. Link Check, a powerful and user-friendly link-checking tool. While Dr. Link Check is primarily designed to find broken links, it’s also excellent for getting an overview of all links on your site, including outbound (external) links.
To get started with Dr. Link Check, visit https://www.drlinkcheck.com/, enter your website’s URL in the text box, and click the Start Check button.

The service will begin crawling your website, starting from the homepage, and will continue until it either reaches the limit of your plan or exhausts all available links. The free “Lite” plan allows crawling of up to 1,500 links, which is sufficient for many smaller websites.
Once the crawl is complete, Dr. Link Check provides several reports accessible from the left-hand sidebar. Since we are only interested in outbound links, select Outbound from the sidebar.

The report may include a variety of link types beyond standard hyperlinks, such as script links (<script src="...">), image links (<img src="...">), and other resource links that may not be relevant to you. To refine the report to display only the links you want, go to the Filter section at the top of the report and select Add → Link Type.

If you plan to check outbound links regularly (which is highly recommended), you can save this customized filter by clicking Save as Custom Report…. This will add a new item to your sidebar for easy access.
Alternatively, if you’d prefer to filter out resource links during the crawl itself, you can instruct the crawler to ignore all links except standard anchor (<a href="...">) links in your HTML code. Note that this option is only available with a paid subscription, starting with the “Standard” plan. To apply this setting, open the Project Settings dialog, expand Advanced Settings, and enter the following rule under Ignore links if…:
HtmlElement != "a"

Once you rerun the crawl, the Outbound report will only display outbound <a> links.
Managing outbound links is key to maintaining your website’s credibility, user experience, and SEO health. With Dr. Link Check, staying on top of these links is simple and efficient. Regular checks ensure that your site remains a reliable resource for both visitors and search engines alike.
In this article, we’ll explore how you can use Dr. Link Check to check the status of multiple URLs or domain names in bulk, without having to manually visit each site.
Go to the sign up page to create a new account (or log in, if you already have one).
Click the Add Project button and paste (or enter) your list of URLs into the URLs to check field (the textbox expands automatically):

The free Lite subscription allows you to check up to 1,500 URLs, while a paid subscription enables you to enter 10,000 URLs at once. If you enter domain names without a protocol (such as http or https), Dr. Link Check automatically prepends them with “http://” to turn them into a valid URL.
As you only want to check the status of single URLs without having Dr. Link Check crawl any linked pages, make sure that URLs to crawl is set to None as shown in the screenshot above.
Now hit the Create Project button to start the check. You will be redirected to the Overview report that gives you a summary of the results.

If you want to see which of the links in your list are broken, select the All Issues report from the sidebar on the left.

Getting a report of links that actually work and are not dead is slightly more challenging. Select the All Links tab from the sidebar and click on Add… in the Filter bar:

Now select Broken check result from the filter list and change Host not found to OK.

Starting with the Professional plan, you can also export your report to CSV format for import into Excel or other spreadsheet software.

In addition to analyzing all links on a single website, Dr. Link Check also enables you to efficiently mass check a list of URLs for dead links. This saves you a significant amount of time and resources compared to manual checks.
A soft 404 is a type of error where a web server returns a 200 OK status code (indicating that the request succeeded), even though the delivered page doesn’t contain the expected content, and a 404 Not Found status would have been the appropriate response.
Think of a page with no or very little content, a page with an error message, or a search results page without any results – that’s what a soft 404 error looks like to you in the browser, despite the server sending a status code 200 in the HTTP response headers as if there were no problem.
Soft 404 errors create a bad user experience, just like regular 404 errors. Clicking on a link, waiting for the page to load, and then not finding the expected content is frustrating and gravely damages the website’s credibility.
It can also impact the site’s search rankings if users encounter a soft 404 and quickly leave the page. Bounce Rate and Time on Page are two important metrics that influence a website’s SEO performance and signal to search engines how relevant and valuable the content is. In addition, soft 404s consume valuable crawl resources, causing search engines to continue crawling unimportant pages instead of important ones, leading to a reduced frequency of crawls, decreased indexation, and ultimately, a negative impact on the website’s search visibility.
Detecting soft 404 errors is tricky. You can’t trust the HTTP status code returned by the server but have to examine the page content. Standard link checkers don’t do this and therefore fail to identify soft 404s.
Our link checking solution, on the other hand, can rely on a large database of content patterns to automatically identify different kinds of soft 404s on a website. Starting with the Professional plan, detected soft errors are reported under the “Soft errors” tab in the sidebar.

An alternative (and free) way to identify at least some of the soft 404 errors is to check out the site’s “Indexing → Pages” report in Google Search Console. This report lists crawl errors, including soft 404s, that Google encountered when indexing your pages.

Another resource you should take a look at is your website’s analytics data. Try finding pages with particularly high bounce rates or low time-on-page values as these are indicators of soft 404 errors.
Last but not least, verify that your server actually sends a 404 status code if a non-existent resource is requested:
404 Not Found error (such as https://www.example.com/this-page-does-not-exist).Control + Shift + I on Windows or Linux, Command + Option + I on macOS).Control + R (or Command + R on macOS) to reload the page.
If the request was not redirected to a different URL and the server responded with code 200, you have stumbled upon a soft 404 error.
Soft 404 errors are frequently the result of an incorrect server configuration or a programming error. Here are two real-life examples:
A website hosted on an Apache web server had a line similar to this in its .htaccess file to configure a custom 404 error page:
htaccess
ErrorDocument 404 https://www.example.com/404.html
Instead of serving the content of the 404.html file directly, the server redirected to the URL https://www.example.com/404.html and returned the 404.html file with a 200 OK status. Changing the line to
htaccess
ErrorDocument 404 /404.html
fixed the issue.
In a different case, a website had a custom “404 Not Found” page with the following PHP code at the top:
php+HTML
<?php header("Status: 200 OK"); ?>
This line resulted in 200 OK being sent instead of the correct 404 code.
Sometimes soft 404s are also remnants of changed website structures or removed content. Products that are no longer available may result in empty search result pages or moved blog posts in empty categories. In situations like these, it can be a good idea to just remove the empty pages or the links pointing to them.
If that’s not possible or practical, you can restrict search engines from indexing the pages by adding a disallow rule to your site’s robots.txt file or including a meta robots tag with the parameter “noindex” (<meta name="robots" content="noindex">) in your pages’ HTML code.
Soft 404 errors can significantly impact a website’s user experience and search engine visibility. Website owners can identify these errors through the use of tools such as Dr. Link Check and Google Search Console and by carefully examining the website’s analytics. Resolving soft 404s may involve reviewing the server’s configuration files and delving into the website’s source code.
When you’re sifting through your website analytics, one of the most important metrics you’ll find is your bounce rate. Bounce rate refers to the rate of visitors that leave your website after a single page visit. This generally means that they didn’t find the page interesting enough to continue browsing your site, let alone buy anything from your business.
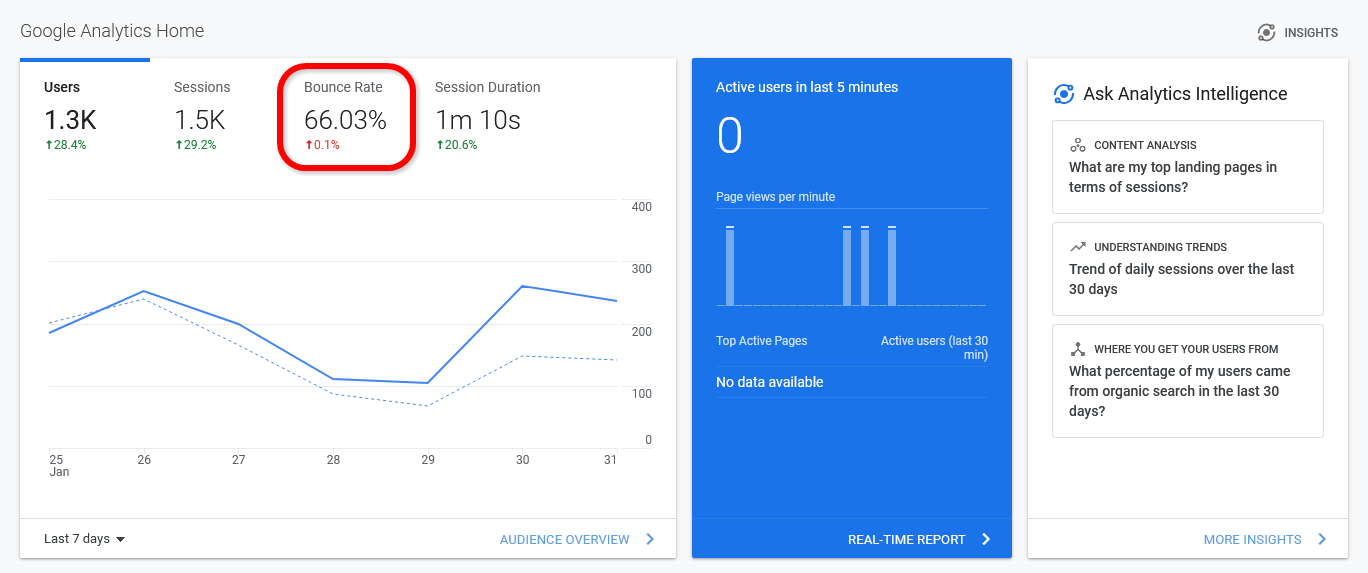
Entrepreneurs should always look for ways to lower the bounce rate of their web pages. After all, a lower bounce rate means that visitors are spending more time browsing your content and your online store, which will lead to more customer conversions and more sales. Fortunately, you can use many smart strategies to reduce your bounce rate and keep visitors around for longer. Here are 11 ways to lower your bounce rate and increase session duration.
Improving the loading speed of your website is one of the best things you can do. This simple change can almost instantly reduce your bounce rate, increase the average session duration of viewers, and enhance your search engine rankings. Of course, this will also have a positive impact on how people react to your website and how many viewers turn into customers.
Tricks such as compressing your content, minimizing HTTPS requests, and allowing asynchronous loading for certain files can help speed up your website. It’s also important to get high-quality hosting. However, to ensure that your website is as efficient as possible, you might want to ask a professional web developer to help you out. Even a 1-second increase in the average loading time can have a significant impact on session duration and conversions.
Another way to reduce your bounce rate and keep visitors around longer is to make your website easier to navigate. If people can’t instantly find what they need on your website, they’re likely to get frustrated and leave. As such, you’ll want to ensure that everything is easy to find and that potential customers have no problem finding what they’re looking for.
Many websites handle this by using large navigation buttons for important parts of their website, such as their online shop and their FAQ page. Providing internal links between pages to link people to things they might be interested in can also help. Asking people to test your website for usability can help you tackle potential problems and improve the ease of navigation.
Encountering a page with missing images or a “404 Not Found” message when clicking on a link is an immediate turnoff for many visitors. Errors like these make your site look unprofessional and unmaintained.
Use our broken link checker service to identify dead links and fix them before they affect your reputation and drive away potential customers.
Sometimes keeping visitors on your website is all about aesthetics. If someone visits your site and finds that it looks like a website from the 1990s, they’ll probably think that your business is old and outdated. Even though less is more sometimes, a visually unappealing website can cause visitors to swiftly leave.
While your website doesn’t need to be too ostentatious, a few visual upgrades and an attractive template can go a long way. You might even want to ask a web design service to help you make your website look as good as possible while still ensuring that it loads fast and is easy to navigate.
Using internal links throughout your website has all kinds of benefits. Internal links can help you improve your Google ranking for certain keywords, which will help you gain more visitors. What’s more, if you use internal linking appropriately, visitors are much more likely to click on these links and keep exploring your website, leading to a huge reduction in your bounce rate.
You should use internal links in your blog posts to link relevant keywords to other helpful pages on your website. You should also include a call-to-action (CTA) on each page that leads viewers to your online store. Adding internal links between relevant products in your online store can also help you keep users browsing and boost your customer conversions.
Adding some enticing interactive content to your blog posts is an excellent way to increase the average session duration of visitors to your website. After all, people will naturally stay on your website longer if they’re watching a video, doing a quiz, or exploring a fascinating interactive infographic.
These features can also help you reduce your bounce rate. When your blog posts offer engaging features like videos, quizzes, and infographics, people will get invested and read more of your content. You can even enhance your sales by using these interactive features to lead people to your online store and including some interactive content on your product pages.
One of the biggest causes of high bounce rates is websites that aren’t mobile-friendly. Many consumers nowadays use their smartphones, tablets, and other portable devices to browse the internet. If your website doesn’t cater to these devices, you’ll lose tons of visitors who would simply rather use a website they can read and browse on their phone.
Making your website more mobile-friendly involves enhancing your layout, making text readable on small devices, and breaking content into small paragraphs to make it easier to read. Once again, you might want to ask a professional web design service for help to make your website more mobile-friendly, especially as it’ll boost session duration and reduce your bounce rate.
If you want to turn more of your website viewers into customers, you need to make sure your online store is fun, appealing, and easy to navigate. The more time people spend browsing your online store, the more likely they are to ultimately buy from you. Naturally, this will also have a great impact on your bounce rate and session duration.
There are a few tricks you can use to keep people engaged in your online store. Adding image links to related products on every product page can catch the attention of viewers. You should also include high-quality product images and even product videos to demonstrate your products. You should make sure your product pages load fast and are easy to navigate on all devices. Including large “Buy Now” or “Add to Cart” buttons can also help boost sales.
Some websites blast visitors with unwanted pop-ups as soon as they visit. Between advertisements, pop-up boxes asking them to accept all cookies, and requests to sign up to an email list, visitors can become frustrated, and these features may cause them to instantly leave a website. As such, you’ll want to avoid them as much as possible.
While you need to ask visitors to accept cookies, you should do so with a small footer rather than a huge pop-up box. You should also avoid big, annoying ads in favor of organic links in your content. Instead of using pop-up boxes to ask people to join your mailing list or check out your products, add these CTAs to your blog pages or somewhere on your website where they’re less obtrusive.
Collecting feedback from website visitors is one of the best ways to improve your website. This helps you instantly discover and solve problems with your website usability. For instance, you might find out that mobile users find it hard to browse your website. You can then work on making your website easier to browse on portable devices.
By finding and tackling these problems, you can impress more viewers, resulting in a lower bounce rate and higher average session duration. You might want to send out feedback surveys to your customers to ask them how easy it was to use your website. You could also pay for usability testing, where impartial testers thoroughly test your website and give you tips on how to improve its usability.
Encouraging visitors to stick around longer on your product pages is one of the best things you can do. The more time they spend browsing your products, the more likely they are to ultimately buy something. As such, you’ll want to optimize your product pages as much as possible to prevent visitors from leaving.
High-quality images of your products can help. Offer pictures from every angle so customers can check out each product thoroughly. Product videos can also help, especially as these can make visitors invest a few minutes into discovering more about each product. Detailed product descriptions and product reviews can also keep people reading and entice them to make a purchase.
If you want to boost your Google search ranking and enhance your sales, lowering your bounce rate and increasing your average session duration can help. By focusing on these analytics and improving them, you’ll keep people around on your website much longer. This will result in a higher rate of customer conversions as well as a significant boost in future traffic.
These 11 strategies can help you significantly improve these analytics and enhance the success of your website. Not only can these tips help online businesses make more sales, but even if you’re not trying to sell anything, decreasing your bounce rate can help you bring more visitors to your site and build a bigger following.
If your website isn’t getting many views despite high-quality content, or if you’re seeing a steady drop in organic traffic, odds are that poor SEO practices are to blame. While plenty of great SEO companies and consultants are available to help you improve your page ranking factors, you might be surprised to learn how much you can do yourself with a minimal understanding of WordPress or HTML.
Before you spend any money on professional services, use this quick DIY audit guide to gauge the quality of your SEO.
SEO involves much more than just keywords. Site speed has been one of the most crucial factors for quite some time – most notably since Google introduced a dedicated page speed update back in 2018. If your site takes more than two seconds to load, it’s likely causing your page rankings to suffer. Data released directly by Google reveals that every extra second that your page takes to load dramatically increases bounce rate (the percentage of users who leave the site after viewing only one page).
Luckily, Google’s PageSpeed Insights tool can tell you exactly how long your loading times are, as well as point out specific areas for improvement so that you or your web developer can make the necessary changes to boost performance, improving both your SEO and user experience.
If your site isn’t optimized for mobile use, it’s time to make that a priority; the majority of online traffic is mobile, and that trend isn’t changing any time soon. In fact, Google now actually indexes the mobile version of websites first, so the lack of an adaptive, responsive, or mobile-first design that makes it easy for people to navigate on their devices will have a sizable negative impact on your ranking.
As with page speed, Google offers free tools to analyze mobile performance and fix any potential problems. Just use Google’s Mobile-Friendly Test to see how your site stacks up.
One of the most basic and most important checks you can run is to ensure that only a single version of your site is being indexed by Google. In an extreme case, search engines could see four different versions of your site:
While this makes no difference to a user browsing your site, it can cause big SEO problems by making it difficult for search engines to know which version to index and rank for query results. In many cases, separate versions of a site can even be interpreted as duplicate content, which further impacts your content’s visibility and rankings.
If you run a manual check and discover a mix of site versions, the easiest fix is to simply set up a 301 redirect on the “duplicate” versions to let search engines know which one to index and rank. Another option is to use a rel="canonical" tag on your individual web pages, which is just as effective as a 301 redirect but may require less time for you or your web developer to implement.
While your site’s performance is a major ranking factor, it’s still important to consider ways of improving your traditional on-page SEO. In addition to creating great, unique content that provides value to the user, you’ll want to look at optimizing title tags, meta descriptions, and image alt tags, as well as improving your internal linking and pulling any bad outbound links.
A number of great tools can help you find any problem areas or opportunities you have missed. Popular options that can quickly provide a list of actionable items include SE Ranking, SEO Tester, and SEMrush’s On-Page SEO Checker tool.
Another great SEO audit tool that focuses specifically on internal and outbound links is Dr. Link Check. It crawls your website and gives you a complete list of all its links. You can then filter that list down to show only the links you are interested in, such as broken links or dofollow links to external websites.
Backlinks are one of Google’s top three factors when determining page rankings, and they can be enormously beneficial when it comes to increasing traffic, as long as they’re legitimate, high-quality links. But there are also so-called “toxic” backlinks that can negatively impact your organic traffic and site rankings. In extreme cases, they can even result in a manual action being taken against your site by Google.
These harmful backlinks are usually the direct result of trying to game the system, whether it’s paying for links, joining shady private blog networks, submitting your site to low-quality directories, or blatantly spamming your links all over the web. While it’s an uncommon tactic, there are also cases of unscrupulous webmasters deliberately using toxic backlinks as a way to sabotage competitors. Even if you aren’t using any of these tactics yourself, it’s still worth doing a periodic check to make sure everything’s above board.
By using a combination of SEMrush’s Backlink Audit tool and the Google Search Console, you can determine whether you have any backlink issues to address. If you do find any problematic backlinks, the two main options are sending out removal requests via email and hoping they get removed, or using the Google Disavow Tool to tell Google that you want them to ignore certain links.
Keep in mind that the point of a DIY SEO audit is to conduct some simple checks that anyone who knows their way around WordPress or basic HTML can handle. If you’ve done everything on this list and still seem to be struggling to gain traction, or if you’re seeing a steady drop in organic traffic, the problem might be something more complex.
In that case, it’s important to know the limits of your own abilities. If you start poking around in code that you aren’t familiar with, there’s a very real risk of doing more harm than good. Hiring someone to fix mistakes is a costly headache that nobody wants to deal with. Instead, consider hiring an SEO specialist with more in-depth knowledge on the subject as soon as you know the problem is something you’re not sure how to fix. The good news is that if you’ve already done a basic audit, that means less work (and billable hours) that a professional needs to do before they can diagnose the issues.
While professional assistance is certainly necessary in some cases, the truth is that many of the most common SEO mistakes can be corrected without much technical know-how, thanks to the robust analytical tools and guidelines available. So before you spend your hard-earned money, walk through the steps outlined in this guide to identify your issues and see if it’s something that can be handled with a few minutes of your or your web developer’s time.
