Broken links send a strong negative signal to visitors: “This website is broken and outdated!” Clearly, that’s not the impression you want your website to make. Dr. Link Check is a simple yet powerful solution that helps you identify broken links before you lose your reputation and your clients.
Enter the address of your website below to start a quick check:
Dr. Link Check starts with the URL you provide and then crawls, page-by-page, through the entire website. In the process, each link has to pass several crucial tests:
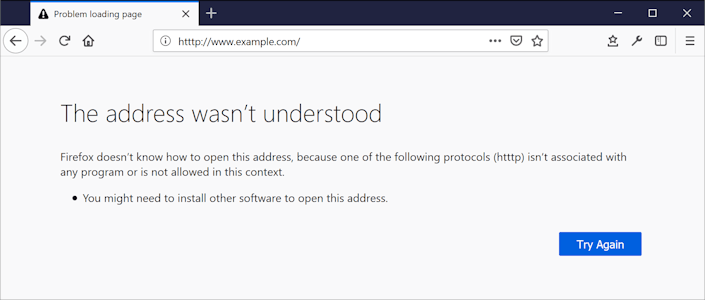
The first step is to check if a link conforms to the rules for valid URLs. This weeds out links like https://www.example,com/ (comma instead of a period) and http:images/example.jpg (missing host). Valid URLs with schemes not verifiable by the crawler (such as tel:+555 1234 5678 or file://server/file.docx) are marked as “Unsupported,” with the recommendation to check them manually. Currently supported URL schemes are http, https, data, and mailto.
In the next step, the hostname extracted from the URL (if available) is translated to an IP address. For this step, the crawler asks a DNS server for the A (IPv4) or AAAA (IPv6) records of the hostname. If no records are available, or the domain’s nameserver doesn’t respond in time, a “Host not found” error is reported.
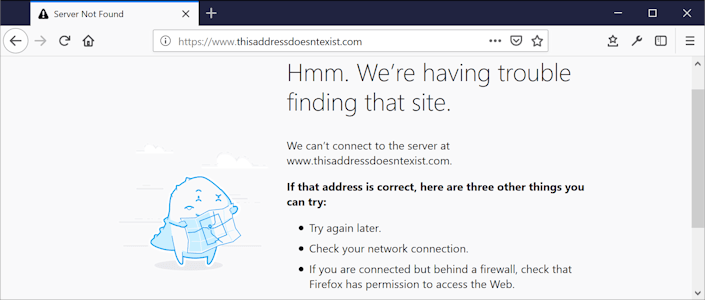
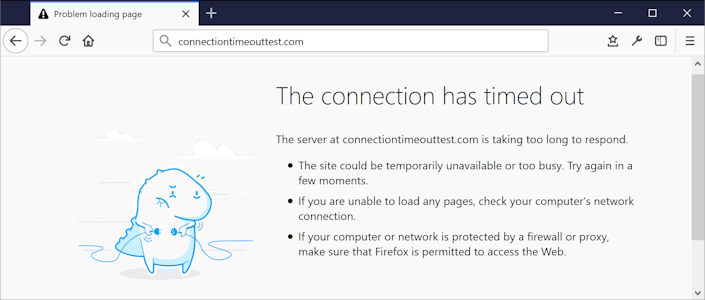
Now that the IP address is known, a TCP connection to the server is established. At this stage, two errors are possible: a “Connect error” if the connection attempt fails, or a “Timeout error” if the connection cannot be established within 40 seconds.
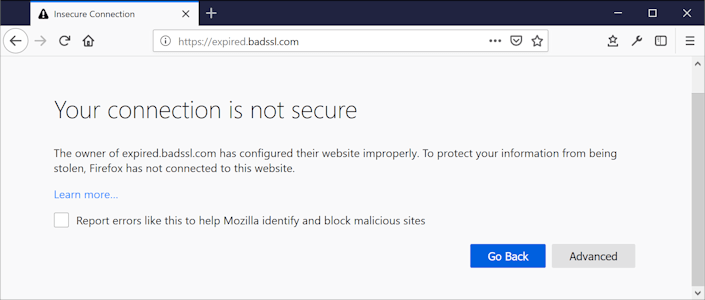
For HTTPS links, the crawler checks for four essential components: 1) the SSL certificate returned by the server is valid, 2) it has been issued by a trusted certificate authority (CA), 3) it’s not expired and 4) it actually belongs to the hostname. In cases where the server only supports obsolete protocols (such as SSLv2 or SSLv3) or cipher suites, the link is marked as broken with an “SSL handshake error.”
When examining the response received from the server, the crawler first checks the value of the HTTP status code: Values in the 2xx and 3xx ranges indicate a correct and successful response, while all other values are considered an error. The most common HTTP status codes are 200 (OK), 301 (Permanent redirect), 302 (Temporary redirect), 403 (Forbidden), 404 (Not Found), and 500 (Internal server error). Redirects are automatically followed up to 15 times, before the crawler gives up with a “Too many redirects” error.
If the server returns an HTML or CSS document, the source code is parsed and discovered links are added to the queue to be checked. The crawler not only looks for <a href> page links, but it also extracts URLs from <link href>, <script src>, <iframe src>, and dozens of more HTML tags and CSS attributes.
Give Dr. Link Check a try yourself, and see how many dead links are on your website right now.